PREP法のデメリットと現代MLでの限界を徹底解説
 Webマーケティング古いPREP法には限界があります。データサイエンスの現場では新しいアプローチが必須です。
Webマーケティング古いPREP法には限界があります。データサイエンスの現場では新しいアプローチが必須です。
- データサイエンティスト
- 機械学習エンジニア
- そして情報系の学生
そんな職業や立場にいる方は、日々大量のデータと向き合い、その精度を上げるために格闘されていることでしょう。
データ分析や機械学習(ML)の分野で、「PREP法」という言葉を耳にすることがあるかもしれません。
PREP法は、一般的にビジネスシーンでのコミュニケーションや文章作成において、
- 結論(Point)
- 理由(Reason)
- 具体例(Example)
- 結論(Point)
の順番で情報を構成し、伝える力を高めるための非常に有効なフレームワークとして知られています。
しかし、データ前処理の文脈で「PREP法」を連想し、「古い」「限界」といったキーワードで検索しているあなたは、その背景にある「データ前処理」の世界でのPREP法(Preparation/前処理)が時代遅れになりつつある現状に意識を向けているのかもしれません。
古いノウハウや方法に時間を費やし、結果が出ないことに悩むのは、あなただけではありません。
現代のデータは複雑で、単なる欠損値処理や外れ値処理といった基本的な作業だけでは対応しきれなくなっています。
今回の記事では、PREP法(Preparation/前処理)が古いと言われる理由を明確に解説します。
- 現代の機械学習の現場で必要とされる最新のデータ前処理
- 特に特徴量エンジニアリングや欠損値処理の最新トレンド
までを徹底的に紹介します。読み終えれば、あなたのデータ分析のスキルは格段に向上し、2025年の最新トレンドに沿った実践的な知識と手法を習得できるでしょう。
スポンサーリンク
コミュニケーションのPREP法とその限界
要点: コミュニケーションで使われるPREP法は、結論から伝えることで相手の理解を助けます。
説得力を向上させる最も基本的な方法です。
しかし、この方法も感情や背景の情報を伝える際には限界があります。
ビジネススキルとしてのPREP法の概要
PREP法は、ビジネスシーンで提案や報告、資料作成を行う際に活用される、簡潔かつ論理的な構成のフレームワークです。
| 要素 | 意味 | 役割 |
| P (Point) | 結論 | 最初に主張を明確に伝え、聞き手の興味を引く。 |
| R (Reason) | 理由 | なぜその結論に至ったのか、根拠を提示する。 |
| E (Example) | 具体例 | 理由を裏付ける事例やデータ、経験を述べる。 |
| P (Point) | 結論 | 最後に最初の結論を繰り返すことで、内容を定着させる。 |
この方法を使うことで、話し方や書き方が整理されます。
短時間で情報を伝達する力が向上します。
特にメールや報告書など、簡潔さが求められる場面で役立ちます。
PREP法のデメリット:論理的な構成が抱える弱点
PREP法は万能ではありません。
その論理的で明確な構成ゆえに、いくつかのデメリットと限界が発生します。
- 感情や背景の欠如:結論を最初に持ってくるため、話の背景や自分の思い、共感を得るための導入が不足しがちです。読者や相手の心を掴む力は弱くなります。
- 長文化への不向き:毎回、結論と理由、具体例を繰り返すと、長文の記事やレポートでは冗長な印象を与える可能性があります。
- 対話での不向き:話す順番が固定されているため、会話の現場や会議で相手の意見を聞くときや柔軟な対応が必要な時には、使いにくいと感じることがあります。
注釈:フレームワーク
考え方や分析の枠組みのこと。複雑な問題を整理し、解決へ導くための共通の手順や構造を提供します。
PREP法の限界:現代ビジネスで求められる要素とのズレ
現代のビジネスやWebマーケティングでは、単に論理的な構成だけでは不十分です。
- 「共感」や「物語」といった感情的な要素
- そしてデータ分析という客観的な事実に基く説明
がより重要視されています。
PREP法は結論中心のため、
- 読者の抱える悩みに寄り添う共感的な部分
- なぜ自分のサービスが最適なのかを語るエピソード的な要素
上記2つが足りなくなりがちです。
結果、読まれても行動につながらない、印象に残りにくい記事や提案になってしまう可能性があります。

スポンサーリンク
古いPREP法の構成では、現代の複雑なデータや情報を全て説明しきることは難しいです。
データ分析におけるPREP法が古いとされる理由
要点: データ分析におけるPREP法(Preparation/前処理)が古いとされる理由は、データ量の爆発的な増加と機械学習の進化により、従来の単純な前処理手法では対応できなくなったことにあります。
データ分析の前提を覆す時代遅れの準備
データサイエンティストにとって、「PREP」とは、一般的にデータ分析の最初の工程である「Preparation(前処理)」を指します。
かつての分析現場では、データの量も少なく、欠損値を削除したり、平均値で埋めるといった単純な手法が中心でした。
しかし、2025年現在、
から日々発生するデータは膨大です。
この時代に、古いノウハウに基づく単純作業としての前処理は、以下の理由から時代遅れと認識されています。
- データの多様性:数値データだけでなく、テキスト、画像、音声といった非構造化データが増加し、単純な手法では処理しきれなくなりました。
- モデルの複雑化:ディープラーニングなどの複雑な機械学習モデルは、特徴量エンジニアリングといった高度な前処理が必要です。
- 時間とコスト:不適切な前処理は、分析全体の時間とコストを無駄にする原因となります。
古い「欠損値処理」の常識とリスク
古いデータ前処理手法の象徴的な一つが、欠損値処理です。
かつてはよく行われていた手法も、現代では大きなリスクを伴います。
- 欠損値を含む行の削除:データ量が少なかった時代は簡単な方法でしたが、現代では大切な情報を失い、結果としてモデルの精度が劣化する原因となります。
- 平均値/中央値による補完:手っ取り早く欠損を埋める方法ですが、データの偏りを生み、外れ値に対して脆弱なモデルを作ってしまう可能性があります。
 データの一部を安易に削除してしまう古い方法は、分析精度を下げる原因となります。
データの一部を安易に削除してしまう古い方法は、分析精度を下げる原因となります。
PREP法の抱える具体的な問題と限界
要点: コミュニケーションのPREP法の限界は、結論優先による共感不足と長文化への不向きです。
共感と長文化を解決するためには、読者の悩みに寄り添う導入部と客観的なデータ分析を加える必要があります。
PREP法 デメリットを補う応用構成
PREP法のデメリットと限界を理解した上で、現代のコンテンツ制作では、その骨格を活かしつつ新しい要素を加えることが推奨されます。
| 新しい要素 | 構成 | 役割 |
| 導入 (S: Summary) | S → P → R → E → P | 最初に結論の概要を述べ、興味を引き、読者の関心を掴む。 |
| 共感 (A: Affect) | A → P → R → E → P | 読者の抱える問題に共感を示し、感情的な繋がりを作る。 |
| 客観性 (D: Data) | P → R → D → E → P | 具体例の前に、客観的なデータ分析の事実を提示し説得力を強化する。 |
結論中心の構成は変えずに、前後に共感や客観的な情報を加えることで、論理的な力と感情的な力の両方を持つ記事を作れます。
複雑なデータ分析におけるPREP法 限界
データ分析におけるPREP法(前処理)の限界は、もはや欠損値や外れ値処理といった単なるデータの整形作業ではなく、より深い知識が必要な領域にあります。
- 特徴量の自動生成に不向き:昔ながらの手法は人間の手作業が中心で、AIを使った特徴量の自動生成や最適化といった最新技術に対応できません。
- データバイアスの無視:データの偏り(バイアス)や倫理的な問題を考慮する機能がなく、結果として差別的な判断を導くモデルを作ってしまう可能性があります。
- 分散データへの未対応:クラウド上に分散して保存されている巨大なデータセットを効率的に前処理する環境や技術が不足しています。
 現代の読者に響くコンテンツを作成するためには、最初に共感の要素を加える必要があります。
現代の読者に響くコンテンツを作成するためには、最初に共感の要素を加える必要があります。
2025年最新のデータ前処理トレンド
要点: 2025年のデータ前処理は、自動化と特徴量エンジニアリング、そして倫理的な配慮を重視する方向へ進化しています。
欠損値処理や外れ値処理も統計的な根拠に基づく高度な手法が中心です。
データ前処理 最新のキーワードは自動化と倫理
古いPREP法の問題点を解決するために、データサイエンスの分野では以下の新しいトレンドが中心となっています。
Auto MLとデータ前処理の自動化
Auto ML(Automated Machine Learning)は、特徴量エンジニアリングやモデル選択、ハイパーパラメータの最適化といった一連の作業を自動で行う技術です。
これにより、人間の手を介していた古い前処理作業が大幅に削減され、時間とコストを節約できます。
注釈:Auto ML
機械学習の一連のプロセス(データ前処理からモデル構築まで)を自動化する技術。AIの知識が豊富でない人でも高度なモデルを作れるようになります。
倫理的AIとバイアス除去への配慮
現代のデータ前処理では、データセットに含まれる性別、人種、地域といった属性の偏り(バイアス)を除去することが重要となっています。古い手法では無視されがちだったこの倫理的な側面は、2025年の最新トレンドの中心となっています。
特徴量エンジニアリング(価値を生む核となる作業)
特徴量エンジニアリングは、古い前処理手法から最も大きく進化した分野です。
単なるデータの整形ではありません。
分析モデルの精度を最大限に高めるために、データから新しい価値を作っていく作業です。
特徴量エンジニアリングの基本と目的
特徴量エンジニアリングとは、手元の生データに含まれる情報を使い、機械学習モデルが学習しやすい、より有用な新しい特徴を作る手法です。
例: 「購入日時」と 「アクセス時間」という2つの特徴から、「滞在時間」や 「購入曜日」といった新しい特徴を作ってモデルに入力することで、予測精度を大幅に向上させられます。
 特徴量エンジニアリングは、データサイエンスの現場ではモデルの性能を決める最も重要な工程です。
特徴量エンジニアリングは、データサイエンスの現場ではモデルの性能を決める最も重要な工程です。
現代に最適化されたデータ処理手法
要点: 欠損値処理は平均補完から機械学習モデルによる予測補完へ、外れ値処理は一律削除から統計的手法による影響度分析へと進化しています。
欠損値処理の最新アプローチ
古い手法では簡単に行削除や平均補完を行っていましたが、現代のデータ分析では情報を最大限に活かすために、より高度な手法が採用されています。
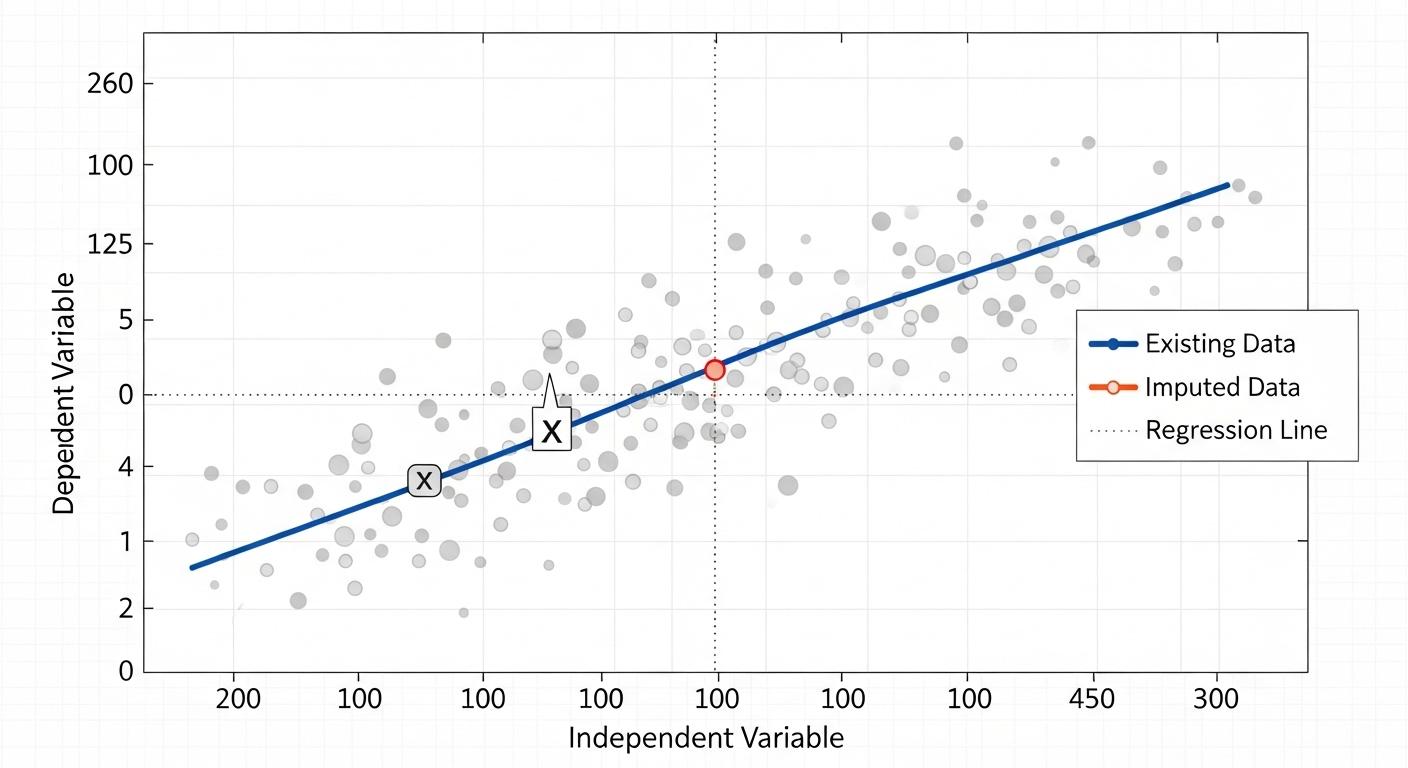
統計モデルによる欠損値補完
欠損値を補完するために、データ全体の分布や他の特徴量との相関関係を考慮して、統計モデル(例:回帰モデル)を用いる手法です。
欠損している値を予測値で置き換えることで、データの全体像をより正確に維持します。
機械学習モデルを用いた多重代入法
最も最新で高精度な手法の一つが、機械学習モデル(例:ランダムフォレスト)を使って欠損値を多重に代入します。
その結果を総合的に評価する方法です。
この手法は、欠損値が発生した理由まで考慮して、最適な補完値を見つけます。
 欠損値処理は、データの傾向を保持したまま、より正確に行う必要があります。
欠損値処理は、データの傾向を保持したまま、より正確に行う必要があります。
外れ値処理の進化:削除から分析へ
外れ値処理も、古い手法のような単なる閾値設定と削除ではなく、その外れ値がモデルに与える影響を分析し、対応を変えるアプローチが主流です。
統計的手法による外れ値特定
外れ値を特定する際に、箱ひげ図(IQR)や Zスコアといった統計的な手法を使って、客観的に閾値を決定します。
感覚的な判断で外れ値を削除する古い方法は避けるべきです。
外れ値のロバスト化と変換
外れ値を発見した後も、安易に削除せず、データの値を対数変換(Log変換)や順位変換などでロバスト化(頑健に)する手法が推奨されます。
これにより、情報を維持しつつ、モデルの外れ値への脆弱性を減らすことが可能となります。
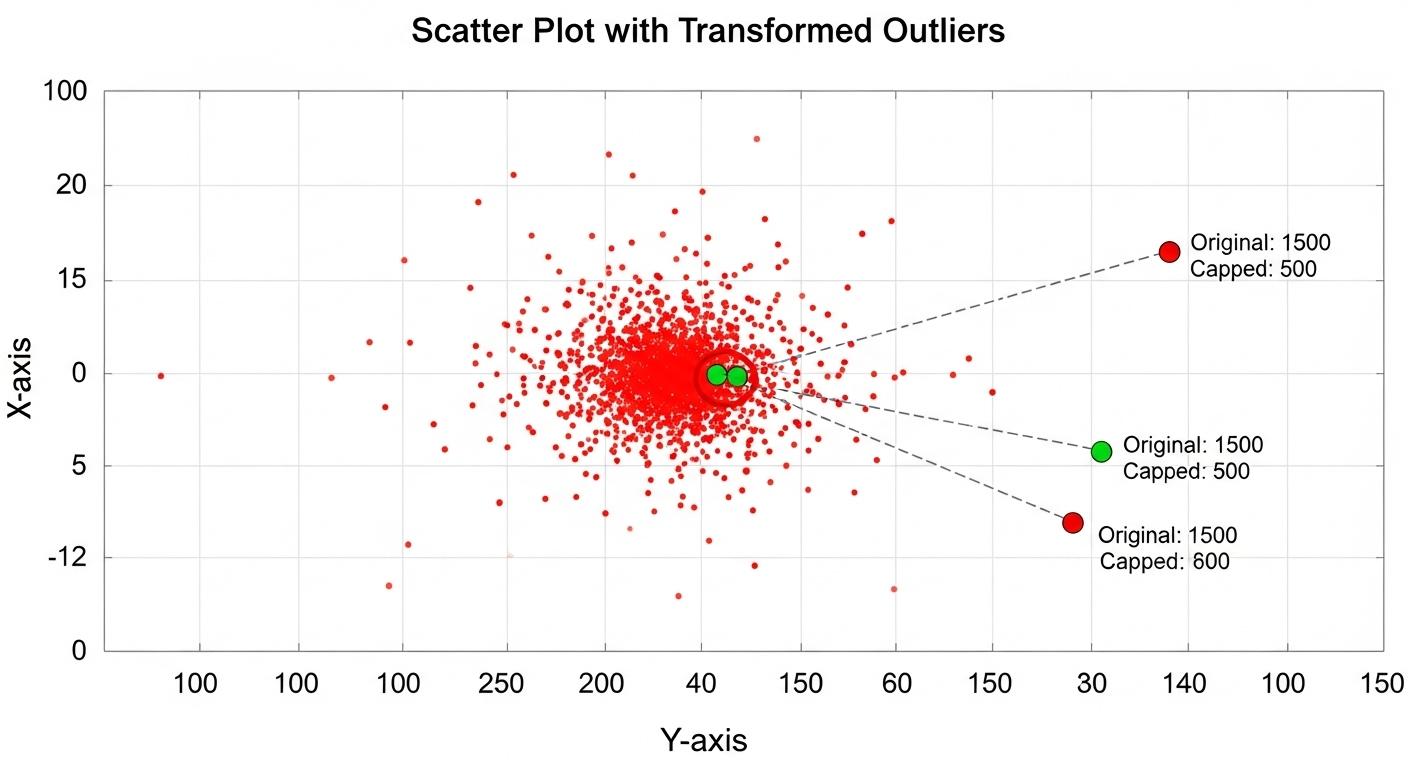 外れ値を削除する代わりに、変換によってその影響を抑制する方法が主流です。
外れ値を削除する代わりに、変換によってその影響を抑制する方法が主流です。
2025年最新トレンドと学習リソースランキング
要点: 2025年のデータサイエンスの学習は、実践中心のプラットフォームと最新の書籍、そしてコミュニティ活動を重視しましょう。
最新のデータサイエンス学習リソースランキング
古いノウハウで時間を無駄にしないために、2025年の最新の学習リソースをランキング形式で紹介します。
これらのツールや書籍は、特徴量エンジニアリングや最新の前処理手法に重点を置いています。
| 順位 | カテゴリ | おすすめリソース | 選定理由(鮮度) |
| 1位 | 実践プラットフォーム | Kaggle (データ分析コンペ) | 最新のデータと手法が常に更新され、実戦経験が積める。 |
| 2位 | 専門書籍 | 『特徴量エンジニアリングの実践』(2024年版) | 欠損値処理や外れ値処理などの最新の手法に特化。 |
| 3位 | オンライン講座 | Coursera (最新の ML コース) | 世界中のトップ大学の最新知識が日本語字幕で学べる。 |
 Kaggleでは、古いPREP法を超える実践的な前処理手法を学ぶことが可能です。
Kaggleでは、古いPREP法を超える実践的な前処理手法を学ぶことが可能です。
データ分析のPREP法に関するよくある質問
要点: PREP法がデータ分析で古いとされる背景や、代わりに使うべき新しいアプローチ、そしてツールに関する疑問に回答します。
Q1. なぜデータ分析の文脈で「PREP法は古い」と検索されるのですか?
A. データ分析の現場では、前処理(Preparation)は分析精度を決める最も重要な工程です。
かつては欠損値削除や平均補完といった単純な手法が主流でした。
しかし、2025年の現在、データの複雑化とモデルの進化により、古い手法では通用しなくなっています。
この課題意識を持つ専門家が、「PREP法 古い」という検索を通じて、新しい解決策を探しているためです。
Q2. PREP法に代わるデータ前処理の「新しいフレームワーク」はありますか?
A. PREP法に代わる単一の「PREP」のようなフレームワークはありません。
現代では、特徴量エンジニアリングを中心とし、データの種類(テキスト、画像)や分析の目的に応じて、様々な手法を使い分けるアプローチが主流です。
例えば、
- データ理解(EDA)
- 特徴量生成
- 特徴量選択
- スケーリング
といった一連の作業を反復的に行うパイプライン思考が重要視されます。
 データ分析は、一方通行のPREPではなく、反復的な改善のサイクルを重視します。
データ分析は、一方通行のPREPではなく、反復的な改善のサイクルを重視します。
現代的PREP法とデータサイエンティストのキャリア
要点: PREP法の骨子(結論先行)は、データサイエンティストのキャリアや報告にも応用可能です。
技術とビジネスをつなぐ力が重要です。
PREP法の骨子である「結論から伝える」スキルは、複雑な分析結果を経営層や他部署の担当者に報告する際に非常に役立ちます。
複雑な分析結果を簡潔に伝える「D→P」アプローチ
データサイエンティストの報告では、分析結果(Data/事実)から最初に結論(Point)を導く「D→P」の構成が効果的です。
- D(Data):最初に「今回の分析で得られた最も重要な事実」を端的に提示します。
- P(Point):その事実から導かれる「ビジネスへの結論(推奨行動)」を明確に述べます。
- R、E、P:その後、分析の理由や具体的な手法、そして最後の結論で締めくくる。
この方法を使えば、専門的な知識がない相手でも、分析結果の価値を理解しやすく、次の行動につながる可能性が高まります。
 データサイエンティストの力は、分析技術だけでなく、結論を的確に伝える力にあります。
データサイエンティストの力は、分析技術だけでなく、結論を的確に伝える力にあります。
まとめと次の行動
要点: 古いPREP法の限界を認識し、特徴量エンジニアリングと最新の前処理手法へ挑戦し、実践を通じてスキルを磨くことが重要です。
古いPREP法を乗り越え、新しい知識を活用
この記事を読んだあなたは、
- コミュニケーションスキルとしてのPREP法のデメリット
- データ前処理の文脈で「PREP法 古い」と検索される背景
- そして 2025年の最新の手法
までを深く理解しました。
次に取るべき行動は、この知識を活かし、あなたの日常の業務や研究に反映させることです。
- コミュニケーション:社内や記事作成では、共感や客観的な事実を加えた「応用 PREP 法」を使い分ける習慣をつけましょう。
- データ分析:安易な欠損値・外れ値処理を避け、統計モデルや特徴量エンジニアリングを使った高度な前処理に挑戦してください。
- スキルアップ:Kaggleなどの実践的な場で、最新の手法を繰り返し練習し、習得することが重要です。
古い方法に固執せず、新しいトレンドに積極的に挑戦する姿勢こそ、データサイエンティストとして成長する鍵です。
📝 サイト外リンク
- Google AI 公式サイト(Auto ML 関連):https://ai.google/
- Kaggle 公式サイト(データ分析プラットフォーム):https://www.kaggle.com/
- Python 公式サイト(データ分析環境):https://www.python.org/
- scikit-learn 公式サイト(特徴量エンジニアリング ライブラリ):https://scikit-learn.org/
スポンサーリンク